 October
22
October
22
Tags
Deep neural networks help us read your mind.
If you let us, we can read your mind.

An image from one of the best (and most famous) decoding studies ever done. Rather than simply selecting which image was shown, the authors actually reconstructed the output image from the brain activity. They also showed that their methods could decode images above chance even with millions of binary images to select from. (Miyawaki et al., 2008)
For the last fifteen years or so, scientists have been able to use measurements of brain activity* to predict what image you’re seeing, what part of your body you’re moving, or whether you’ll remember something you were studying (See Norman et al. 2006 for a review). While impressive–some might say scary–these “decoding” abilities are often quite limited; they can be more like parlor tricks than usable mind-reading technology. In some instances, they worked only because experimenters limited the number of things the subject could be doing, such as looking at one of ten different images or moving one of just a few body parts.
On the other hand, if we understood how every possible event activates your brain, then we could easily reverse-engineer what caused your current brain activity. For example, if we understood how an image is transformed by your brain to some internal representation, we could directly predict brain activity for any image. This approach is called “encoding”.
Encoding is much harder to do than decoding (see Naselaris et al., 2011 for a nice review). Decoding doesn’t require any idea about what “code” the brain is using to process and store information. The information is already stored in the brain, and the model uses that brain activity to predict what was seen, as best as possible. The encoding model, on the other hand, attempts to predict the brain activity itself. To do so, it makes an explicit guess at how information is transformed from an external stimulus into some representation in the brain. To date, only a few simple encoding models have been built (e.g. Kay et al., 2008; Naselaris et al., 2009; Gurclu et al., 2014) and, while results have been promising, they haven’t revolutionized how we understand brain function.

Depiction of a deep “convolutional” neural network. Each layer does either (a) a “convolution” operation (multiplying a local area of the image (“patch”) with a small “filter”, to see how well the image patch matches the feature represented by the filter, or (b) a maximum operation, where the maximum filter response in the local area is selected over other filter responses. Image (c) Jeremy Karnowski.
In a recent paper, scientists from Donders Institute for Brain in the Netherlands wondered whether deep neural networks could be used to predict brain activity. Neural networks are computer algorithms that are inspired by brains but, despite their name, capture very little of the brain’s anatomy and dynamics. Despite this limitation, some computer scientists speculate that neural networks capture the essential computations of brains; neuroscientists have remained skeptical. This paper, published in the Journal of Neuroscience by computer scientists, addresses this disagreement.
Neural networks: brain-inspired computing
A few basics about neural networks help in understanding the “magic” of the paper. Neural networks are computer programs that simulate one way that brains compute: individual units (roughly inspired by neurons; hence the name) combine inputs from other “connected” units to compute an output. In slightly more technical terms, a unit computes a weighted sum of all of its inputs; that sum becomes it’s output.
With this simple operation, a set of input pixels from an image can be input to compute edges, edges used as input to compute shapes, and shapes used as input to identify objects. By stacking these operations–or layers–one after another into a deep neural network, a single neural network can take an input image at its first layer and accurately output which object (amongst 10,000) is contained in the image at its final layer. The magic of the deep neural network is that no neuron is told what to compute–each one figures it out simultaneously and gradually, as the network’s predictions are compared to the true is given feedback on how well it predicted objects in the images.

An example from Google’s “Deep Dream” neural network, which uses an input image to generate a new image. This is one of the worst examples, but it’s an open-license image 🙂 Check elsewhere for cooler ones, such as here.
These algorithms have been in use since the 1980’s; big data and seemingly limitless computational power have unleashed their dormant power. Now, networks are trained on millions of labeled images, with tens of millions of parameters, in days or weeks. Neural networks are behind a slew of start-up companies, and the largest companies have already snapped up the top researchers to start new projects (Facebook’s AI, Google Brain, and Baidu). These algorithms are behind products you know (SIRI) and have even begun to be used for art. They’re powerful enough that they’ve evoked real concerns of an “AI singularity” from serious minds, such as Stephen Hawking and Elon Musk–a topic reviewed I hope to return to in a future post. and

Deep neural network for learning an artistic style, then applying it to an input image (Gatys et al., 2015)
Even though neural networks seem to work by magic from the outside, we understand quite well how and why these larger networks are able to solve tasks that smaller ones were not. Modern computational power allows neural networks to have more neurons, and these neurons have been used to have more layers. With more layers, the network can learn the mapping between pixels and object categories one small piece at a time. It’s too hard to map directly from pixels to object categories directly; a car can appear in an image with a different size, position, orientation, shape and color. Instead, the networks use the first few layers to learn features common to all objects: edges, corners, contours, and color opponency. At later layers, the network can learn to piece these common features into features diagnostic to groups of objects, and finally to individual object categories. With fewer layers, the network can’t solve the problem in such a progressive fashion, and the process fails.

For some types of tasks (e.g. for images presented briefly and out of context), it is thought that visual processing in the brain is hierarchical–one layer feeds into the next, computing progressively more complex features. This is the inspiration for the “layered” design of modern feed-forward neural networks. Image (c) Jonas Kubilias
It’s thought that the brain uses a similar “layered” tactic for learning objects; “early” visual cortex (getting more direct input from the eyes) computes simple “features” (such as edges), then sends the output of that computation to the next visual area. Each visual area computes a slightly more complicated feature than the area it receives input from (simply because the input it receives has already been transformed by the previous area; by the time these computations reach decision-making areas of the brain, they’re sufficiently abstract that object recognition (or any other task) can be done relatively simply.
Predicting real brain signals from neural networks
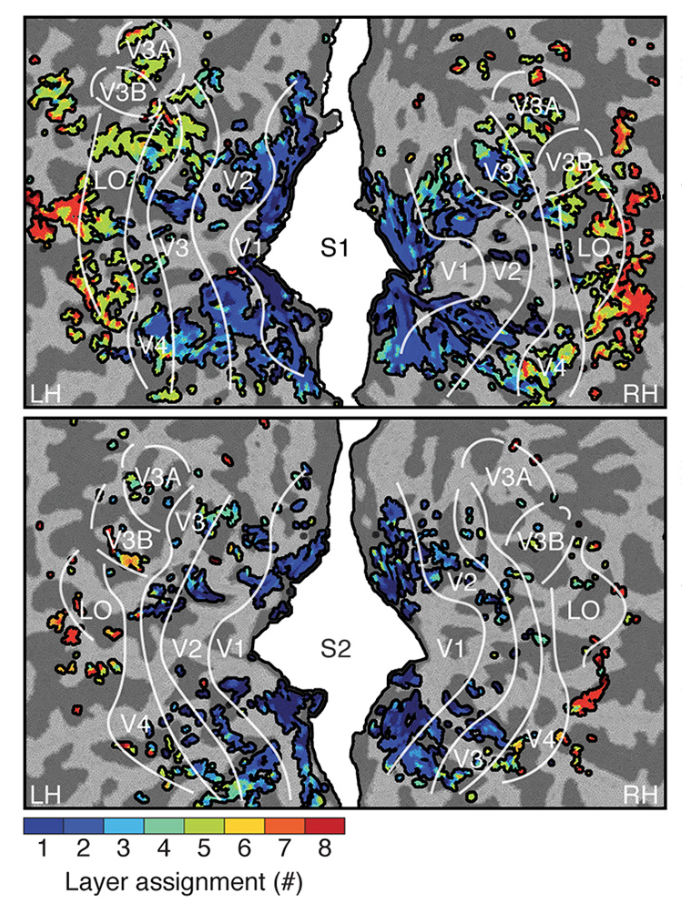
Images of the visual areas of two brains (top and bottom; left hemisphere to the left and right hemisphere to the right). Brains are flattened to remove wrinkles (light and dark grey) so that it’s easier to see. Cooler colors represent earlier layers of the neural network; warmer later. Note that cooler colors are in earlier visual areas (V1, V2), and warmer in later layers (V4, LOC), showing a correspondence between model and brain. (Guclu & van Gerven, 2015)
Predicting brain signals from deep neural network is not as complex as you might think. To do so, the authors first trained a deep neural network to recognize which one of 10,000 object exists in an image, for over a million of images. These networks learn this task very well; after training, the scientists presented new images to both the neural network and to individuals in an MRI scanner, recording the activity in both. Finally, the authors used a simple mathematical computation (linear regression) to predict activity at a location in the person’s head from the neural network’s activity. They repeated the procedure for each location in the brain. In order to see which layers of the neural network predicted activity in each visual area in the brain, the authors predicted the activity at each location separately for each neural network layer. For each location, one of the layers best predicts that location’s activity, and so that layer is assigned to that location (see the figure to the right). Using this procedure, the authors could determine whether “deeper” layers of the neural network predicted activity in “deeper” areas of the brain.
The neural network’s activity predicted the human brain activity–in fact, these predictions are the most accurate ever made for the MRI data. In addition, there was a clear mapping between the neural network and brain: activity in the brain’s “early” visual cortex was predicted best by “earlier” layers of the neural network, whereas brain activity in “deeper” areas of the brain that compute more complex properties, such as the type of object seen, were predicted best by “deeper” layers of the neural network. The correspondence between the neural network and the brain was stronger than even the most optimistic computer scientists would have predicted.
Conclusion
Encoding models can predict brain activity from an event; building encoding models will allow us to read your mind. A recent paper creates the world’s best encoding model from a deep neural network, a computer algorithm at the forefront of computer vision and artificial intelligence research. This encoding model not only predicted the brain activity well, but its hierarchical structure also mapped onto what has been though to be a hierarchy in visual areas in the brain. The relationship between the neural network and brain were greater than neuroscientists and computer scientists could have expected.
* fMRI signals, which are used in most encoding/decoding studies, and all of those I refer to here, do not indicate brain activity directly; instead, they indicate differential flow of deoxygenated blood. I use the term “activity” throughout the post as (a) encoding and decoding are not limited to fMRI and (b) I couldn’t edit this post to clean up the terminology and keep things clear.
References:
Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. “A Neural Algorithm of Artistic Style.” arXiv preprint arXiv:1508.06576 (2015).
Güçlü, Umut, and Marcel AJ van Gerven. “Deep Neural Networks Reveal a Gradient in the Complexity of Neural Representations across the Ventral Stream.” The Journal of Neuroscience 35.27 (2015): 10005-10014.
Kay KN, Naselaris T, Prenger RJ, Gallant JL. Identifying natural images from human brain activity. Nature. 2008; 452(7185):352–5.
Naselaris T, Prenger RJ, Kay KN, Oliver M, Gallant JL. Bayesian reconstruction of natural images from human brain activity. Neuron. 2009; 63(6):902–915.
Naselaris, Thomas, et al. “Encoding and decoding in fMRI.” Neuroimage 56.2 (2011): 400-410.
Miyawaki, Yoichi, et al. “Visual image reconstruction from human brain activity using a combination of multiscale local image decoders.” Neuron 60.5 (2008): 915-929.
Norman, Kenneth A., et al. “Beyond mind-reading: multi-voxel pattern analysis of fMRI data.” Trends in cognitive sciences 10.9 (2006): 424-430.

Pingback: Биомимикрия: природа как будущее инноваций